1. Intro
Goal: To tune hyper-parameter in machine learning or deep learning, using bandit algorithm, to minimize the time usag
Methods used with
- SGD
- Tree ensembles
Idea: Try a large number of random configurations, but takes a lot of time. So hyperband:
- Run just an iteration (random configuration) or two at first
- Evaluate how they perform
- Using earlier results to select candidates for longer runs
e.g, following experiments: max iteration:81
Runs Iteration 81 1 27 3 9 9 3 27 It starts with 81 runs, one iteration each. Then the best 27 configurations get three iterations each. Then the best nine get nine, and so on
2. Learning Rate: Tune or Not
“Low learning rate with many iterations” is good for XGBoost
If we do not tune learning rate, the hyperband make good sense
3. Implementation
Just need two function
- one return a random configuration
- another one train that configuration for a given number of iterations and return a loss value
4. Experiment
To evaluate the performance of hyperband, we did several experiment. From the high level, we want to answer two major question:
- How hyperband perform in different machine learning algorithms.
- How hyperband perform compared to other hyper parameter tuning algorithms
4.1. Setting
In our experiments, we are making a binary classification problem. For the dataset, we choose Breast Cancer Wisconsin (Diagnostic) dataset, features are computed from a digitized image of a fine needle aspirate (FNA) of a breast mass. They describe characteristics of the cell nuclei present in the image.
According to Algorithm 1, we set $R=81$ and $\eta=3$, which means maximum iterations per configuration is $3$ and configuration downsampling rate is $3$
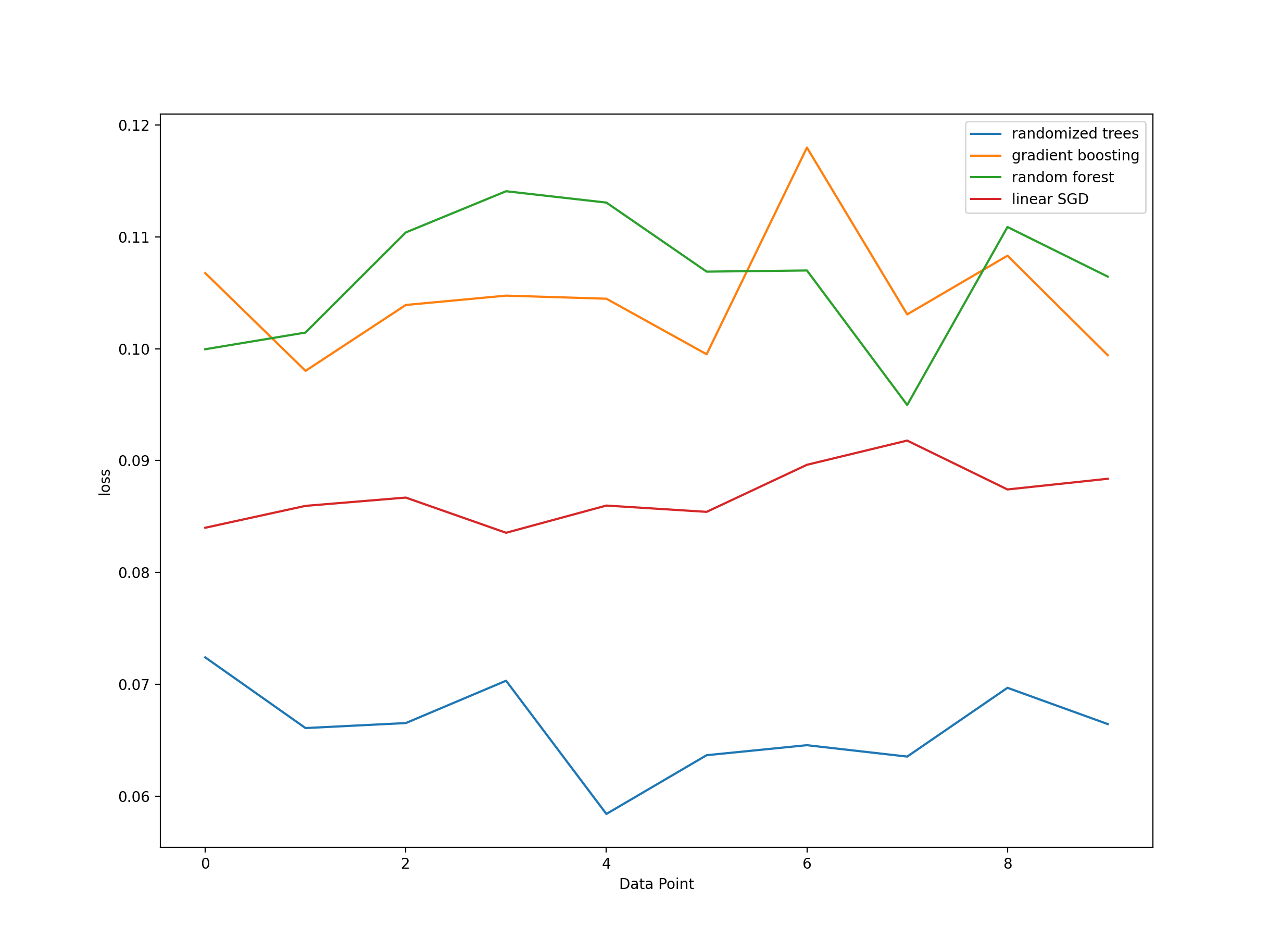
To evaluate the performance of hyperband in different machine learning algorithms, we choose gradient boosting, random forest, extremely randomized trees and linear SGD. To compare between different methods, we use log loss as our metric
From the figure below, we can observe that after few iterations, the hyperband algorithm has the ability to optimize the parameter of these machine learning algorithm and make good prediction with low log loss.
To compare the performance of different parameter tuning method, we choose 5 candidate.
- Grid search. this method would explore the whole hyperparameter space, every combination given by the space
- Randomized search. In contrast to Grid search, a fixed number of parameter setting is sampled from the given parameter space
- Halving Grid Search, based on grid search and apply successive halving strategy, all candidate would be evaluated with a small amout of resource at first and iteratively select the best candidates
- Halving Randomized search, based on Randomized search and apply successive halving strategy, all candidate would be evaluated with a small amout of resource at first and iteratively select the best candidates
- hyperband
Grid based search algorithms are time consuming, since the overall search space is quite large. On the opposite, randomized search algorithms is efficient but the output is unstable, which means the results highly depend on the randomized initial configuration.