1. Abstract
深度神经网络有很多参数因而威力巨大。但是过大的神经网络使得过拟合成为了一个非常严重的问题。Dropout是解决这个问题的一个方法。其主要思想是在训练过程中随机舍弃一些单元,而验证这种方法效果的方式也很简单:通过和不经过Dropout,而大小与经过Dropout的模型相近的神经网络模型进行对比。通过实验,这种方法能够很好地防止过拟合,并且和目前的一些正则化方法相比有了明显的提升。
2. Introduction
深度神经网络包含了许多非线性隐藏层,这使得深度神经网络变得有很强的表达性,也就是说其可以学习输入和输出之间的复杂的关系。
但是当训练数据有限的时候,可能部分关系是从采样噪声学到的,这些关系在训练集中存在但在实际的测试数据中不存在。这就导致了过拟合。
减少过拟合的方法包括,验证集上的性能开始下降时尽快停止训练,为权重引入L1/L2正则惩罚项。
如果计算量上不受限制,按照bayesian的黄金准则,regularize 一个固定规模的模型的最好的方式是,在参数的所有可能的取值上做预测,再根据每种取值的后验概率对这些预测加权取平均。实际中希望用更少的计算量近似到达bayesian的性能。
本文提出dropout,学习指数个共享参数的模型,做预测,求几何平均。近似地有效地组合了指数多个神经网络体系结构。
Dropout做法,暂时地随机地移除网络中的单元(及其输入和输出连接)。比如,每个单元都以固定的概率$p$(比如=0.5)保留。(但是输入单元的保留概率应该接近1),相当于从原网络中采样一个thinned稀疏的网络。 原网络有$n$个单元,则有$2^n$种可能(每个节点有移除/保留2种可能,各节点独立)的稀疏网络。
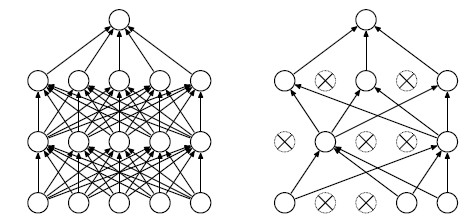
在测试的时候,直接地先对每个网络做预测再平均 计算量大不可行。采用近似平均方法,将$2^n$个网络组合成一个神经网络(所有单元都保留,但单元的输出权重都乘以该单元在训练时候的保留概率),基于这个神经网络做预测。
3. Motivation
Dropout的动机来自于关于性别在进化中的作用的理论。有性生殖包括从一个亲本和另一个亲本中提取一半的基因,加入非常少量的随机突变,并将它们结合产生受精卵。无性繁殖是通过父母基因的拷贝中加入微小突变来创造后代。无性繁殖应该是一种更好的方法来优化个体的健康,这似乎是合理的,因为一组良好的基因组合在一起可以直接传递给后代。另一方面,有性生殖很可能会破坏这些共同适应的基因,特别是如果这些基因的数量很大,而且直觉上,这应该会降低已经进化出复杂的共同适应的生物体的适应性。然而,有性繁殖是最先进的生物进化的方式。
对有性生殖优势的一种可能解释是,从长期来看,自然选择的标准可能不是个体特性,而是基因的混合能力。就是说那些能够和更多随机的基因协作的基因才是更加健壮的。因此一些基因必须要自己学会做一些事而不只是跟很多其他基因合作,这种合作会减少个体适应性。类似地,随机的选择dropout可以增加隐层神经元的健壮性。
有个密切相关但却略有不同的例子,十个阴谋,每个五人参与和一个大阴谋五十人参与相比,显然前者获得一次成功概率较大。一个复杂的共同协作的网络在训练集表现会很出色,但到测试集中,出现了很多新的数据,他就不如很多个更为简单的协作神经元工作的效果好。
4. Model Description
考虑一个有着$L$层隐藏层的神经网络,让$l \in {1,….,L }$ 表示隐藏层的层数,让$z^{(l)}$ 表示输入到第$l$c层神经网络的向量,$y^{(l)}$ 表示第$l$层神经网络的输出,$W^{(l)}$表示第$l$层神经网络的权重,$b^{(l)}$表示第$l$层神经网络的bias
$$
\begin{aligned} z _ { i } ^ { ( l + 1 ) } & = \mathbf { w } _ { i } ^ { ( l + 1 ) } \mathbf { y } ^ { l } + b _ { i } ^ { ( l + 1 ) } \ y _ { i } ^ { ( l + 1 ) } & = f \left( z _ { i } ^ { ( l + 1 ) } \right) \end{aligned}
$$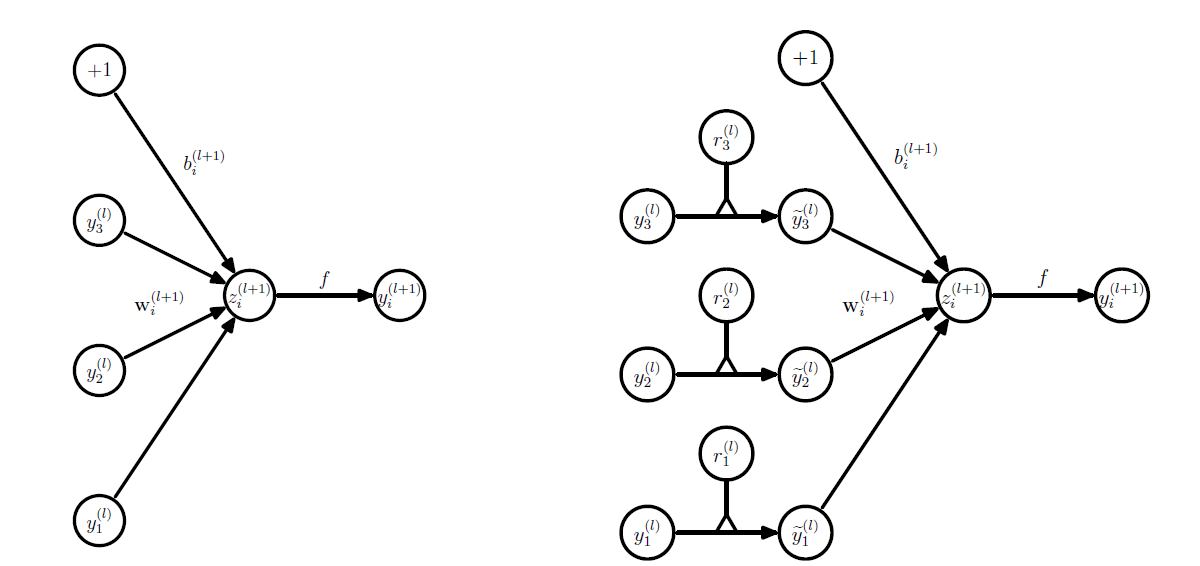
左图:普通神经网络。右图:dropout之后的神经网络
$$
\begin{aligned} r _ { j } ^ { ( l ) } & \sim \text { Bernoulli } ( p ) \ \widetilde { \mathbf { y } } ^ { ( l ) } & = \mathbf { r } ^ { ( l ) } * \mathbf { y } ^ { ( l ) } , \ z _ { i } ^ { ( l + 1 ) } & = \mathbf { w } _ { i } ^ { ( l + 1 ) } \widetilde { \mathbf { y } } ^ { l } + b _ { i } ^ { ( l + 1 ) } \ y _ { i } ^ { ( l + 1 ) } & = f \left( z _ { i } ^ { ( l + 1 ) } \right) \end{aligned}
$$
5. Conclusion
Dropout是一种可以在神经网络中减小过拟合程度的一种方法。普通的反向传播算法只能在学习到训练集中的知识但是泛化性能不够。而随机的Dropout使得每一个隐藏层的单元都不一定会在输出中起到作用,因此能够提升神经网络在各个领域内的使用性能。
Dropout的一个缺点是它使得训练的时间延长了,通常来说,一个使用Dropout来训练的神经网络会比拥有相同结构的普通神经网络耗费2-3倍的时间,这主要是因为变量的更新较为缓慢,每一次更新都是几乎不相同的结构。当然有得必有失,在机器学习的领域中,要想获得一方面的进步,就要在其他方面做出让步。Dropout方法增加了算法的训练时间,降低了模型的过拟合风险。